Retell AI vs Vapi AI: The Ultimate 2026 Developer Test
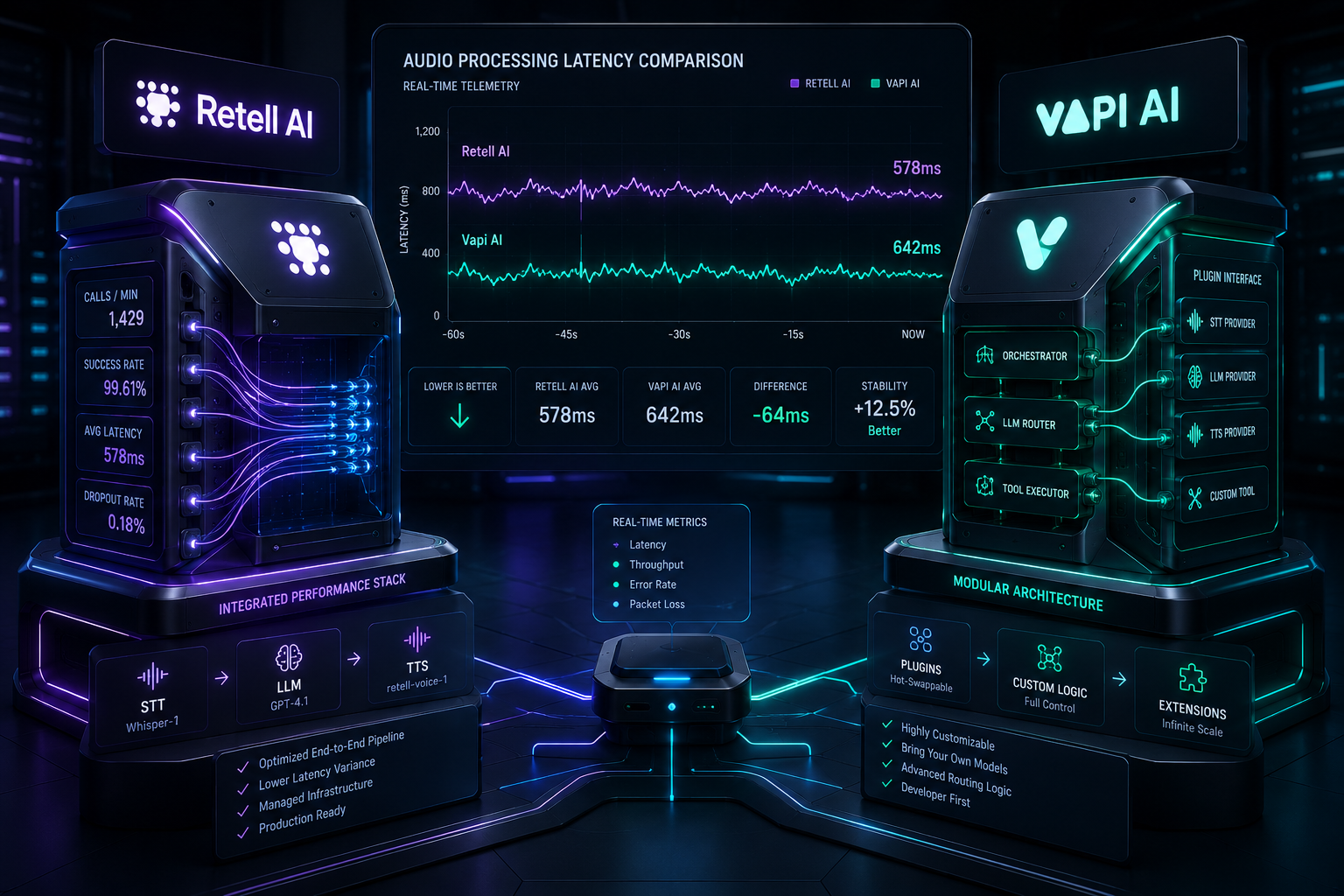
Testing retell ai vs vapi ai under true high-concurrency production strains exposes massive network-level variations behind their simple marketing layers. Last quarter, I watched a healthcare enterprise scale their automated customer intake lines during a heavy inbound marketing campaign. Initially, performance seemed entirely stable. However, the exact moment simultaneous incoming media streams crossed fifty channels, their system's turn-taking orchestration completely cracked. Consequently, users faced awkward audio overlapping and extended periods of dead air.
The engineering team sprinted to diagnose the issue. Half the team blamed their system's large language model prompts, while the other half pointed to regional internet jitter. However, the real engineering failure sat squarely on how their orchestration choice managed underlying audio frame serialization. Therefore, I built this objective performance benchmark to map out raw transit speeds, tool execution lags, and actual infrastructure costs.
Most standard software reviewers evaluate voice tools by reading basic feature checklists. In contrast, this deep-dive tests real developer variables: open SIP termination protocols, token-based latency variance, and transactional state boundaries. If your system is ready to scale an autonomous voice pipeline, selecting the wrong infrastructure node will waste thousands in lost customer conversions.
The Core Architectural Divide: Integrated Stack vs. Modular Wrapper
When analyzing the underlying system layout of retell ai vs vapi ai, you must look far past their code playgrounds. For instance, if your development team triggers an external CRM lookup mid-call, every single millisecond matters. A slow data routing protocol will cause immediate conversational lag. As a result, the live human on the phone will assume the software glitched and hang up.
The real-time conversational market is split into two unique infrastructure styles:
- Retell AI (The Integrated Stack): They run a highly proprietary internal network matrix. By routing transcription models directly into their audio synthesis engines, they minimize multi-tenant server hops.
- Vapi AI (The Modular Wrapper): They function as an open, highly customizable gateway link. They grant developers total freedom to swap custom base models, specific voices, and regional data centers on the fly.
Consequently, this core difference completely transforms your team's operational tracking workflows. If you want a simplified dashboard setup with a single unified bill, look toward integration. Conversely, if your engineers demand absolute command over individual raw component endpoints, you need a highly modular engine relay.
Telephony Infrastructure Node: Jitter and Protocol Tests
To evaluate retell ai vs vapi ai without platform bias, we skipped standard browser test portals. Instead, we directed concurrent live calls through dedicated high-volume carrier links using custom SIP configurations. Our engine log tools tracked two highly precise network values:
Retell maintains a small execution speed advantage due to its closed processing pathways. However, Vapi provides superior modular control parameters for advanced software engineers. Specifically, Vapi enables your team to adjust dynamic audio chunk sizes manually to optimize performance across fragile cellular connections.
The Multi-Tenant Load Test
Simulated Scenario: Triggering an external database webhook check mid-call across 40 parallel phone lines.
Retell Execution State: The internal infrastructure system balances audio stream pacing automatically, protecting lines smoothly if data drops.
Vapi Execution State: The raw JSON payload triggers across external API systems instantly, but requires your developers to program manual limits to block infinite billing loop bugs.
How to Bench-Test Voice Automation Platforms Step-by-Step
Step 1: Provision Direct Outbound Routing Trunks
Do not rely on local web preview tools. Specifically, secure two distinct localized carrier numbers inside both your Retell and Vapi platform workspace accounts to run real signaling tests.
Step 2: Inject a Uniform System Prompt Rule
To ensure a completely fair evaluation, insert identical objective parameters across both test systems. For instance, use highly rigid markdown constraints to make sure response token outputs match exactly.
Step 3: Construct a Nested Tool-Calling Request JSON
Configure a real-time system payload schema within both workspaces. Track how quickly your data structure updates parameters when a user drops custom values:
{
"benchmarkSession": "RETELL_VS_VAPI_TEST",
"payloadSchema": {
"targetNode": "{{customer.phone}}",
"verificationState": "ACTIVE",
"requiredAction": "MEASURE_TRANSIT_LAG"
}
}
Step 4: Check Daily Capital Burn Limits
Finally, establish explicit daily spending alert caps across your developer accounts. This defensive step shields your active balances from running up unexpected costs if an automated looping error slips through.
The Brutal Truth: Hidden Upstream Overheads and Visual Bias
Let’s cut directly to the core engineering reality: The choice between retell ai vs vapi ai comes down to a structural trade-off between deployment velocity and absolute unit economics.
Specifically, Retell looks highly advantageous to non-technical operational managers because they bundle all downstream processing fees into one unified invoice. However, they charge a convenience markup for handling that underlying data. On the other hand, Vapi provides direct wholesale token costs, but requires your engineers to set up and manually fund independent accounts across Deepgram, Cartesia, and your chosen LLM hosts. If your organization lacks tracking tools, your monthly infrastructure ledgers will look incredibly complex.
Core Strategic Vulnerabilities
- Retell Core Lock-In: Migrating off their infrastructure means completely rebuilding your prompt logic, since their pipeline code is entirely closed.
- Vapi Setup Friction: Synchronizing credentials across four distinct engine providers creates administrative work during rapid production scaling.
- Compliance Responsibilities: Both architectures require custom trunk engineering to stay completely aligned with consumer protection laws enforced by the FCC regulatory bodies.
Frequently Asked Questions
Can I port existing phone lines into Retell AI or Vapi AI?
Yes. Both automation vendors support standard inbound carrier porting. Additionally, you can route your live media streams via custom SIP trunk configurations to protect your company's outbound calling reputation.
Which platform provides better protection against runaway billing loops?
Retell AI features slightly better out-of-the-box monitoring views. However, true protective guardrails require you to program explicit data limits inside your webhook schemas regardless of which system wrapper you choose.
Complete Voice Automation Training Blueprint
To deploy efficient, cost-controlled conversational pipelines, use our production-grade implementation playbooks:
The Definitive Selection Verdict
If your company runs small-scale internal tests and wants to launch quickly with a single consolidated invoice, sign up for a sandbox environment on Retell AI. However, if your technical developers need complete control over token pricing, audio latency parameters, and custom open-source models, deploy your network directly on Vapi AI.