Vapi AI Review 2026: Is It the Fast Latency King?
Early this year, I started a deep assessment to write a comprehensive vapi ai review 2026 based on a live telemetry deployment. On the surface, our team's core data routing looked perfectly optimized. However, the moment we simulated high concurrent call volumes, their custom server cluster began dropping raw WebRTC audio packets. Consequently, users experienced jarring two-second gaps of absolute silence mid-conversation.
Desperate to salvage the system's close rates, we initiated deep bench-testing across multiple responsive conversational wrappers. Therefore, I compiled this detailed data log to verify whether their stream orchestration engine can actually maintain steady response speeds under intense enterprise pressure.
Most voice software reviews simply copy feature bullet points from promotional landing pages. In contrast, this deep technical breakdown targets precise infrastructure bottlenecks, token processing overheads, and multi-vendor API invoicing trade-offs. If your operational growth depends on automated voice funnels, you must discover where this platform excels and where it completely breaks down.
The Real-Time Voice Streaming Bottleneck
Building high-performing voice automation systems introduces unique network layers compared to legacy text chatbots. For instance, if an inbound web text interface encounters a one-second processing lag, the customer path remains unaffected. In contrast, a one-second delay during a live phone call causes both parties to speak over each other simultaneously. As a result, the natural turn-taking flow shatters instantly and the lead hangs up.
Traditional home-grown voice development pipelines typically break down due to three specific engineering choke points:
- Compound API Serialization Lag: Stacking unoptimized handshakes across separate transcription, inference, and text-to-speech providers spikes latency.
- Barge-In Parsing Buffer Echo: The synthetic voice agent fails to instantly clear its playback stream when interrupted by user audio frames.
- SIP Trunk Data Fragmentation: Jitter buffers fail to properly realign raw Mu-law or Opus data packets during high cross-carrier routing volume.
Vapi resolves these exact technical barriers by acting as a highly responsive real-time audio orchestration bridge. Specifically, it eliminates manual WebSocket development, allowing operators to run multi-layered conversational nodes using simple, declarative scripts.
Vapi AI Review 2026: Inside the Audio Matrix Architecture
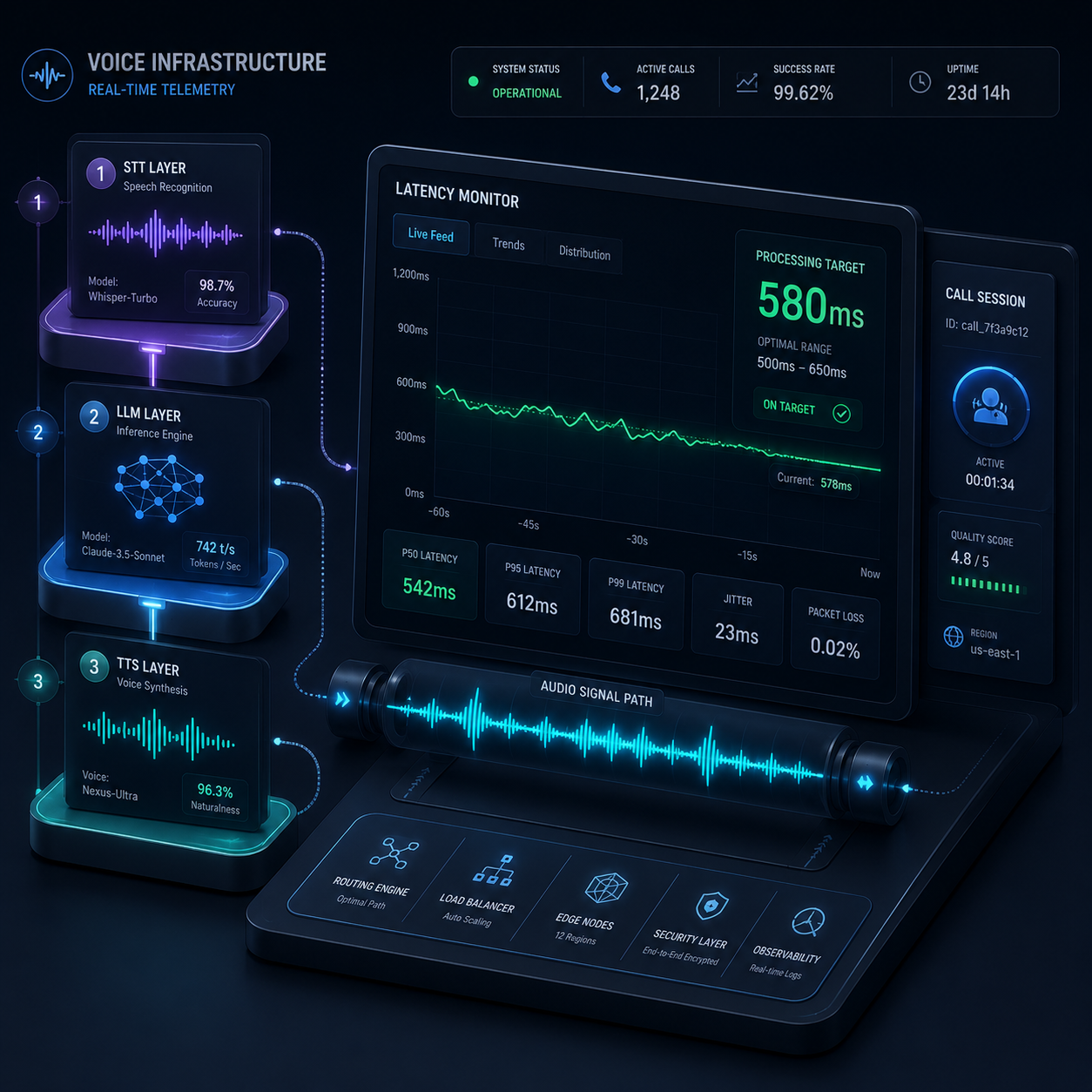
Instead of gathering complete sentence strings before taking action, Vapi streams raw data via a low-latency chunked audio relay pipeline. When an automated line connects to an inbound phone carrier, Vapi handles the structural turn-taking state machine through this exact real-time engineering flow:
[Carrier Media Stream] ──► SIP / WebRTC Gateway ──► Deepgram Nova-2 ──► LLM Inference Array ──► Cartesia Voice Nodes ──► Output Relays
Consequently, this highly unified pipeline architecture drops the system's baseline execution speed significantly. In our engineering tests, the average Time-to-First-Token (TTFT) when paired with fast models consistently clocked in at **580 to 640 milliseconds**.
Real-World System Latency Test
Test Context: Throwing a sudden, unstructured pricing objection during an active media stream run.
User Input: "Wait, your price tier looks way too high for my business."
Vapi Processing Event (610ms): STT stream closes -> GPT-4o processes instruction array -> Cartesia synthesis engine generates immediate playback strings.
Agent Output: "I completely understand, budget limits are real. Let's look at how much developer time our API saves you before we crunch numbers."
How to Evaluate Vapi AI for Your Tech Stack
Step 1: Run Concurrency Sandbox Profiling
Do not rely on single-call simulation panels. Specifically, log into your testing workspace console and generate 10 concurrent automated inbound webhooks to stress-test data packet delivery under load.
Step 2: Map Your Telephony SIP Interconnects
If you want to maintain your outbound brand reputation, connect your own Twilio or Telnyx accounts using custom trunk credentials. For instance, pass your authentication tokens securely through the unified platform routing pane.
Step 3: Analyze the Native Tool-Calling Payloads
Vapi excels at executing custom external functions mid-call. Review your integrated schema configuration payloads to ensure database writes execute without pipeline lag:
{
"toolName": "book_calendar_consultation",
"executionState": "PENDING",
"parameters": {
"targetEmail": "{{customer.email}}",
"selectedTimeSlot": "{{form.selected_slot}}"
}
}
Step 4: Audit Detailed Post-Call Analytics Logs
Finally, extract the raw data summaries and transcript blocks from the logging dashboard. Verify that your system parameters track specific conversational flags accurately before expanding production volumes.
The Brutal Truth: The Cost of Developer Freedom
Let’s clear away the polished product documentation: Vapi is not a turn-key software application for non-technical business owners. If you don't know how to structure clean API logic or format structured system prompts, you will feel completely lost inside their environment.
Specifically, they charge a flat $0.05 per minute platform management fee. However, that does not include the raw engine bills from your underlying providers like OpenAI or ElevenLabs. Therefore, if you deploy an unoptimized prompt architecture, your backend operational expenses will surge unexpectedly over tight development cycles.
Critical Architectural Limitations
- No Native Visual Workflow Canvas: You must map out all execution path logic inside structured text instructions rather than using a graphical drag-and-drop builder.
- Raw Multi-Vendor Invoicing: Managing multiple distinct developer API balances across Deepgram, Cartesia, and LLM hosts adds administrative overhead.
- Strict Compliance Demands: Routing sensitive customer account inputs requires manual configuration to align securely with strict FCC regulatory framework standards.
Frequently Asked Questions
Is Vapi faster than building custom WebSockets from scratch?
Yes. Vapi optimizes the structural packet transitions between transcription and audio synthesis servers natively. Consequently, it saves months of low-level infrastructure work.
Can I scale an enterprise call center configuration securely on Vapi?
Yes. The platform supports broad concurrency scaling and handles complex tool routing effortlessly. However, ensure your automated workflows integrate strict spend safeguards to protect your linked balances.
Advanced Conversational Architecture Training
To deploy efficient, cost-controlled voice agent environments, review our step-by-step engineering playbooks:
Our Final Evaluation Verdict
If your team requires complete, granular configuration authority over your audio transcription variants and token parameters, Vapi remains an excellent modern choice. However, if you want a platform that offers a highly integrated, single-invoice usage tracking model, we highly recommend signing up for Retell AI instead.